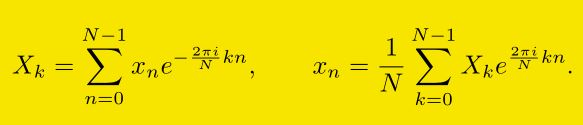A los números X0,...,XN-1
descritos en la primera fórmula se los llama transformada de Fourier
discreta (o DFT por sus siglas en inglés) de la sucesión x0,...,xN-1.
La transformada inversa de Fourier discreta (o IDFT) de la sucesión X0,...,XN-1 está dada por los números x0,...,xN-1 de la segunda fórmula.
En la literatura no hay una definición estándar de la DFT, sino que
se pueden encontrar otras versiones con distintos signos y factores de
normalización.
De manera similar, la transformada de coseno discreta (DCT) de la sucesión x0,...,xN-1 tiene diferentes versiones, lo mismo para la transformada de coseno inversa discreta (IDCT )de la sucesión
Ondas de sonido
La onda sonora que representa el audio es una función continua definida
en el intervalo finito [0,T]. El sonido analógico se lo digitaliza
tomando cierta cantidad de muestras por segundo, y almacenando estas
muestras ("samples") de manera digital con cierta precisión ("bit
depth").
Por ejemplo, en un CD de audio
tenemos:
Tasa de muestro (o sample rate): 44100 (se toman 44100 muestras por
segundo, o 44.1 kHz)
Calidad de sonido (o Bit Depth): 16 bits (cada muestra se almacena
en una variable de 16 bits) Bitrate =
44100*16*2 =1.411.200 bit/s = 1.41 Mbit/s si el sonido es estereo.
Esto es, 1.41/8 = 0.1764 MB/s o 10.58
MB/min.
Eliminación de frecuencias bajas
Dado un vector X con las frecuencias de un sonido, buscamos eliminar un cierto porcentaje de frecuencias bajas.
Veamos un ejemplo de como eliminar un 50% de las frecuencias en un vector X de tamańo 5.
En X guardamos las frecuencias
posición
0
1
2
3
4
X
4
6
1
9
3
Queremos eliminar de X las frecuencias mas pequeńas. Para ello hacemos
lo siguiente.
En F ordenamos las frecuencias de manera descendente
posición
0
1
2
3
4
X
4
6
1
9
3
F
9
6
4
3
1
En indices guardo la posición que ocupaba originalmente en X en
elemento F
posición
0
1
2
3
4
X
4
6
1
9
3
F
9
6
4
3
1
indices
3
1
0
4
2
nos quedamos con cuanto=0.5 (50%) de las frecuencias, esto es,
cuantasFrecuencias=2
posición
0
1
2
3
4
X
4
6
1
9
3
F
9
6
4
3
1
indices
3
1
0
4
2
F
9
6
4
0
0
Utilizando indices, volvemos los elementos de F a la posición original
que tenían en F
posición
0
1
2
3
4
X
4
6
1
9
3
F
9
6
4
3
1
indices
3
1
0
4
2
F
9
6
4
0
0
X
4
6
0
9
0
Veamos la implementación en Python de esta idea:
import
matplotlib.pyplot as plt#paquete para graficar import numpy as np#paquete de operaciones
matemáticas from scipy.io import wavfile#paquete para cargar
archivos wav from scipy.fftpack import dct, idct#paquete para dct y idct
# leemos el archivo wav frec, x =
wavfile.read('audio1.wav')
# el audio es estéreo,
para simplificar nos
quedamos con un solo canal x = x[:,1]
# calculamos la DCT
# cuidado, sino normalizamos idct(dct(x)) no da x X = dct(x, norm="ortho")
# en F guardo las
frecuencias ordenadas de manera
ascendente F = np.sort(np.abs(X))
# en indices[k] guardo
la posición que ocupaba
originalmente en X en elemento F[k] indices = np.argsort(np.abs(X))
# quiero que F esté
ordenado descendientemente (sort
ordena ascendente) F = F[::-1]
indices = indices[::-1]
# X es del tipo "list"
lo paso al tipo
"array de numpy" Xantes = X
X = np.array(X)
F = np.array(F)
# nos quedamos con
“cuanto” de las frecuencias (1=100%) cuanto = 0.5
cuantasFrecuencias = int(len(X)*cuanto)
cuantaEnergia = np.linalg.norm( X[
indices[range(0,cuantasFrecuencias)]
] )/np.linalg.norm(X)
# al resto de las
frecuencias las ponemos en 0 X[
indices[range(cuantasFrecuencias+1, len(X))] ] =0
# reconstruimos el
sonido con las nuevas frecuencias xx= idct(X, norm="ortho")
print("Frecuencias totales:", len(X))
print("Frecuencias que consideramos:",cuantasFrecuencias, "que
conforman el", cuanto*100,"% de la energia")
# guardamos el nuevo
sonido wavfile.write("Naudio.wav",
frec,
xx)
#graficamos la
seńal/frecuencias viejas/nuevas fig1 = plt.subplots()
plt.plot(Xantes, 'r,')
plt.plot(X,'g,')
Exhibimos aquí algunos resultados para diferentes
valores de Q(o sea, de la variable "cuantaEnergia")
Q
Frecuencias
Frecuencias
no eliminadas
%
wav
1
147200
147200
(original)
0
0.999
147200
95667
35.1
0.99
147200
95667
63
0.98
147200
39444
72.9
0.97
147200
31755
78.5
0.95
147200
22493
84.8
0.92
147200
15177
89.7
0.89
147200
10969
92.5
0.85
147200
7498
95
0.77
147200
3870
97.3
0.73
147200
2856
98.1
0.60
147200
1084
99.3
0.45
147200
329
99.8
0.30
147200
76
99.95
Aquí está el código Python del archivo del ejemplo descargar.
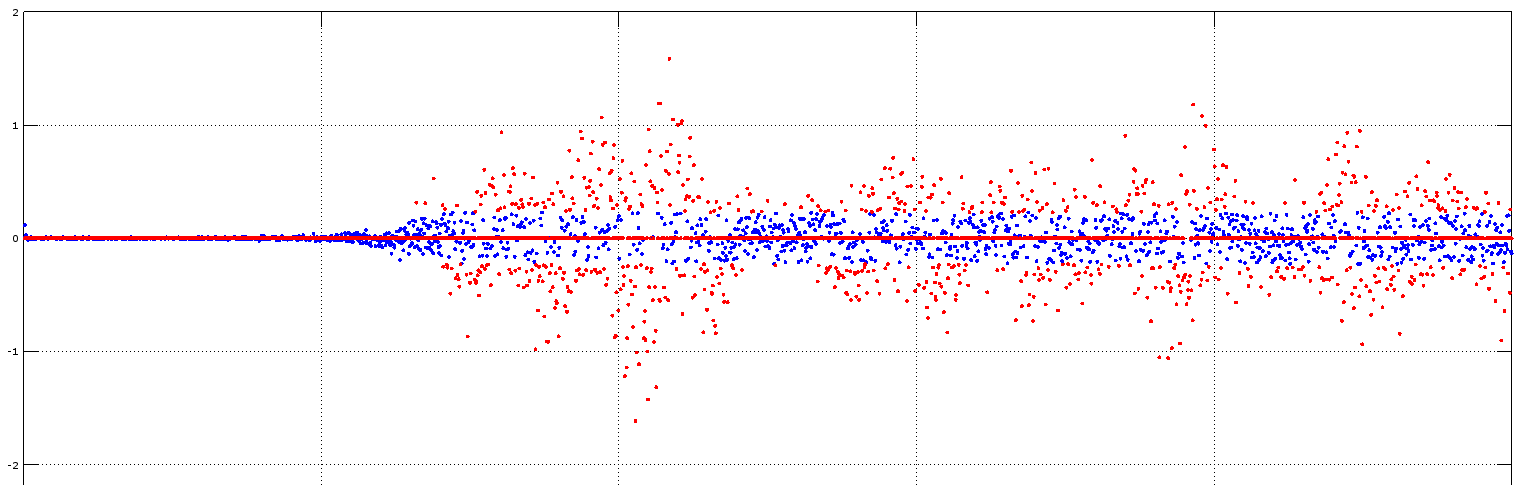
Tomamos Q=0.8. Aquí se ven los
primeros 2500 coeficientes del vector X, en color rojo se ven aquellos
necesarios para alcanzar en 80% de la energía. Todos los puntos azules
son descartados.
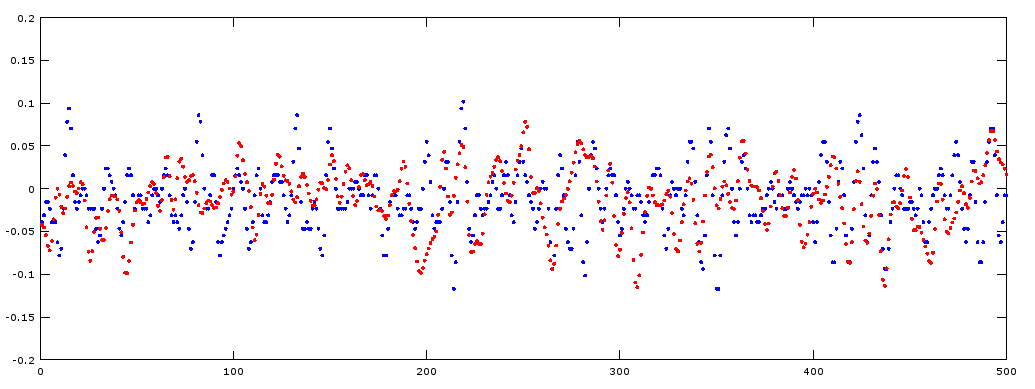
Con Q=0.8. En azul vemos los valores del sonido original x. En rojo
vemos los valores reconstruídos a partir de los coeficientes que bastan
para alcanzar el 80% de la energía original.
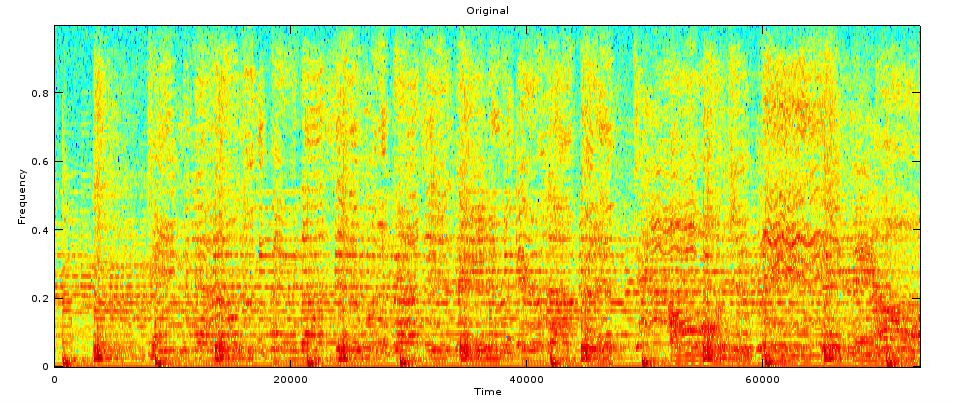
Histograma del sonido original. Los rojos corresponden a coeficientes
altos, bajando con naranja, amarillo, verde, celeste, y azul significa
coeficientes nulos.
Histograma del sonido "comprimido". Los rojos corresponden a coeficientes
altos, bajando con naranja, amarillo, verde, celeste, y azul significa
coeficientes nulos.